
Cosa sono le Applicazioni Web?
Origini, motivazioni e contesto attuale di queste componenti essenziali della moderna Internet
Ne avrete sentito parlare. O forse no. In ogni caso, ci avete a che fare tutti i giorni. Proprio ora state interagendo con una applicazione web, quella che genera le pagine di questo sito. In questo articolo vedremo di cosa si tratta e perché le applicazioni web sono oggi così importanti.

Le origini
Il World Wide Web (WWW - letteralmente traducibile come rete globale, o più semplicemente web) è stato inventato da Tim Berners-Lee nel 1989 presso il CERN (Consiglio Europeo per la Ricerca Nucleare, vedi immagine di copertina), oggi il più importante centro di ricerca al mondo per lo studio delle particelle elementari.
Il web era principalmente una risposta alle necessità di condivisione di informazioni in ambito di ricerca. Il CERN avrebbe potuto brevettare l’idea, ma non lo fece, anzi nel 1993 rilasciò il web con licenza pubblica (vedi la Figura seguente), mantenendone semplicemente la proprietà intellettuale. Questa scelta fu l’inizio di una rivoluzione che continua ancora oggi.
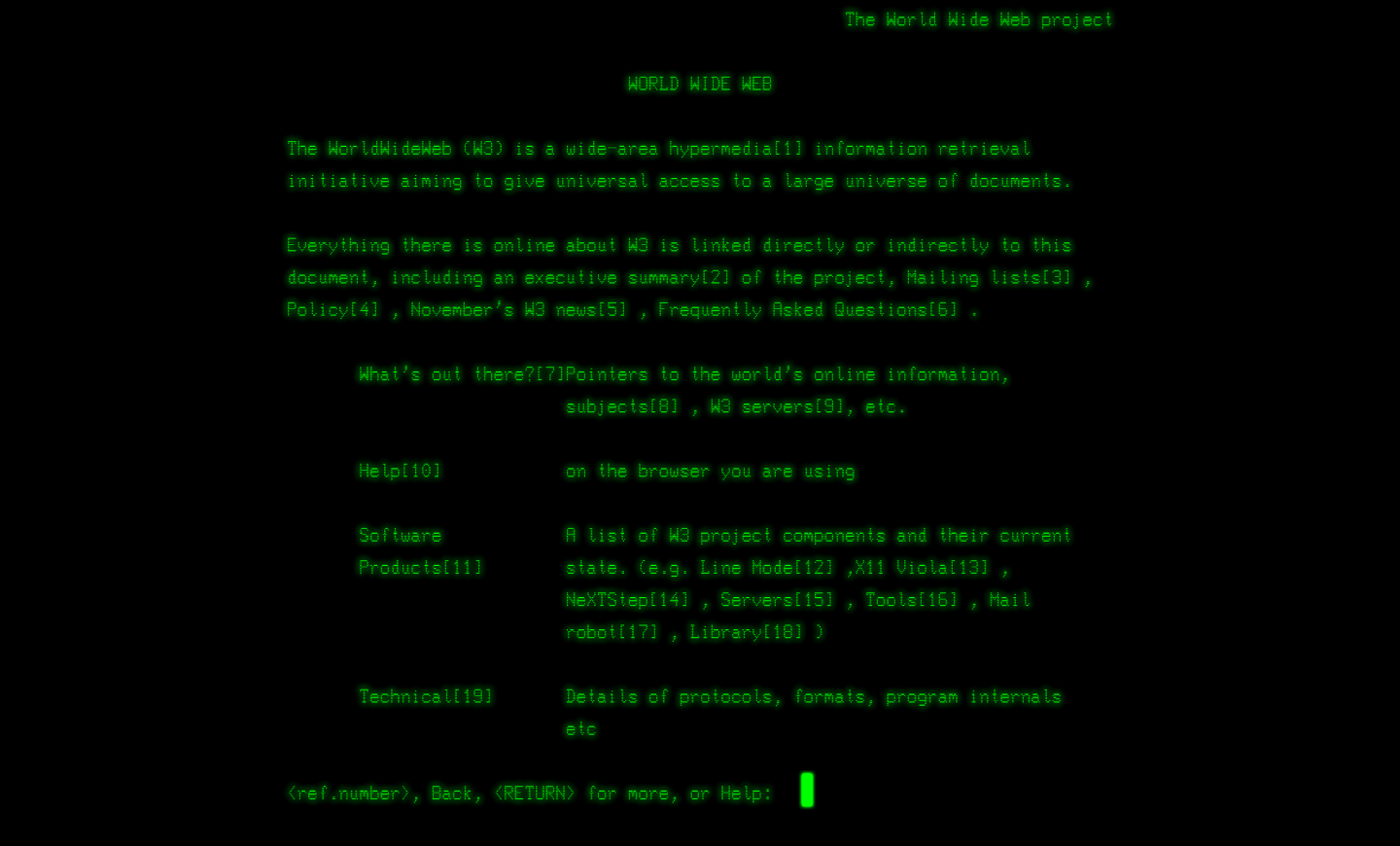
Il meccanismo base
Il web è un sistema distribuito per lo scambio di documenti e informazioni, basato su una architettura client-server. Il server è un sistema costantemente attivo, tipicamente raggiungibile da remoto (attraverso la rete delle reti "Internet"), in attesa di essere interrogato. Il client è invece un sistema capace di interrogare il server e recuperare le risposte contenenti l’informazione richiesta.

Il linguaggio della comunicazione è stabilito da un protocollo standard (HyperText Transfer Protocol - HTTP), oggi diffuso in tre principali versioni (HTTP versione 1.1, 2 e 3) come specificato nella "Request For Comments" (RFC 9110). Nei sistemi web moderni la comunicazione è sempre più bidirezionale e asincrona per supportare funzionalità interattive. In particolare, dopo una prima "discussione" in HTTP (tecnicamente handshake – letteramente “stretta di mano”), il server può inviare dati senza che il client faccia alcuna richiesta esplicita (es. per inviare notifiche in tempo reale) attraverso protocolli standard come WebSocket (RFC 6455).
Nelle moderne implementazioni, come buona pratica di sicurezza, lo scambio di messaggi avviene all'interno di un canale cifrato che protegge la confidenzialità dell'informazione e permette al client di autenticare il server, attraverso un protocollo di più basso livello per il trasporto (Transport Layer Security - TLS, ultima versione 1.3 - RFC 8446).
Le applicazioni web
In origine il web era sostanzialmente un archivio di documenti statici (file) ospitati su server, liberamente consultabili da chiunque. L’aggiornamento dell’informazione su questi documenti era tipicamente a cura degli stessi amministratori di sistema. La necessità di meccanismi flessibili per l’inserimento e la consultazione dell’informazione ha portato alla creazione delle cosiddette applicazioni web, ovvero veri e propri programmi in grado di elaborare, memorizzare e presentare a video le informazioni scambiate fra client e server web.
Oggigiorno, le applicazioni web sono lo standard de-facto per la realizzazione di servizi e interfacce utente su Internet (persino le app sul vostro smartphone!)
Le applicazioni web moderne sono programmi molto complessi, perché si basano su un’ampia gamma di interpreti sia lato client che server, a vario livello di astrazione e diversa localizzazione sulla rete. Spesso il codice eseguibile è distribuito su diversi server, appartenenti a reti ed organizzazioni diverse. Risulta quindi difficile delinearne in maniera precisa il perimetro. Inoltre, gli input/output, i linguaggi di programmazione, le tecnologie utilizzate sono estremamente variegati.
Un esempio concreto
Ad esempio, vediamo cosa succede quando inserite una chiave di ricerca (es. world wide web) sul vostro browser o su un widget motore di ricerca preferito (es. basato su webkit) sul vostro smartphone. In questo caso, il sistema contatterà un indirizzo del tipo: https://www.google.com/search?q=world+wide+web.
Il vostro client (browser) effettuerà tre principali operazioni a diverso livello di astrazione:
- Identificare l'indirizzo IP corrispondente al nome di dominio www.google.com (tramite richiesta al Domain Name System – DNS);
- Attivare un canale di comunicazione cifrato (TLS) con il server web che ascolta sull’indirizzo IP identificato;
- Inviare un messaggio di richiesta HTTP "GET /search?q=world+wide+web" attraverso il canale cifrato.
E sul server...cosa succede?
Il messaggio di richiesta viene interpretato dal server web di Google per individuare quale programma eseguire (applicazione web associata al percorso /search) e quali input inviargli (variabile q=world+wide+web, nota: lo spazio viene codificato col segno +).
L’esecuzione dell’applicazione web /search fornisce in uscita un testo codificato in Hypertext Transfer Markup Language (HTML) che viene inviato in risposta al browser attraverso il canale cifrato.
Cosa succede ora sul browser?
L’interpretazione del contenuto HTML lato client innesca automaticamente:
- ulteriori richieste su altri indirizzi/risorse web;
- interpretazione di contenuti in altro formato:
- Binario come immagini o video;
- Cascading Style Sheets (CSS) per determinare aspetto e struttura dell’interfaccia;
- JavaScript per rendere interattiva l’interfaccia utente;
L’interpretazione di CSS ed in particolare JavaScript può determinare a sua volta nuove richieste verso ulteriori indirizzi/risorse web. JavaScript rappresenta in effetti lo standard de-facto per l’implementazione delle componenti client delle applicazioni web (codice eseguito sul client, piuttosto che sul server).
Pensate che la singola ricerca precedente genera in cascata oltre 50 richieste verso server associabili a Google. La Figura seguente mostra in maniera gerarchica i server (nomi di dominio diversi associati ad ogni nuvoletta) contattati nell'ambito di questa singola richiesta.
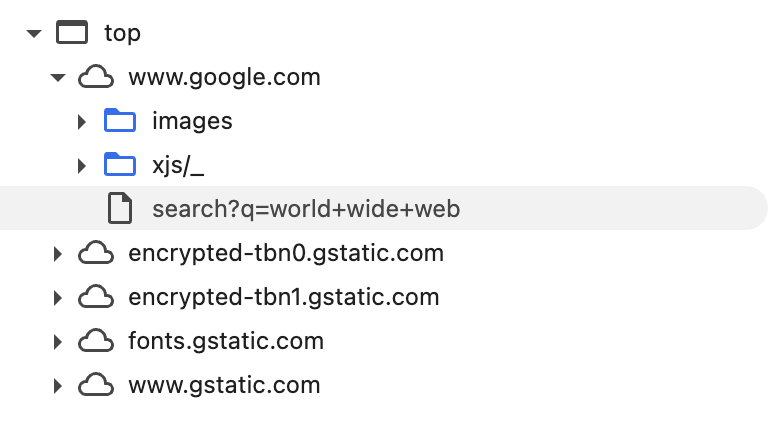
Notate che le richieste coinvolgono server/nomi di dominio diversi da quello di partenza. Questo è un caso tipico, vista la natura distribuita della moderne applicazioni web. Aspetto invece peculiare del nostro esempio è che tutti i server sono riconducibili alla stessa organizzazione (Google, o più precisamente la holding Alphabet Inc).
In una applicazione web tipica su Internet le richieste associate coinvolgono organizzazioni diverse da quella associata al nome di dominio di partenza, in maniera totalmente invisibile e trasparente all’utente.
Ebbene, indovinate un pò, è stato stimato che l’80% dei servizi web su Internet utilizzano risorse associabili a Google (che quindi può tracciare le vostre attività, a prescindere dal fatto che usiate o meno i suoi servizi o se chi fornisce i servizi utilizzi esplicitamente Google per il tracciamento utente). In tale situazione, esistono innumerevoli modi attraverso cui Google può tracciare il comportamento dell’utente. Il metodo più immediato è osservare un campo dell’intestazione delle richieste denominato Referer, che tipicamente i browser includono in ogni richiesta, ed indica da quale indirizzo proviene il codice che ha generato la richiesta.
Approfondiremo in altre puntate i metodi per migliorare la nostra privacy sul web. Per il momento, spero di avervi dato alcune informazioni chiave per comprendere cosa siano e quanto siano centrali le applicazioni web nella moderna Internet.
Scopri altri articoli con etichette simili